It’s not entirely uncommon to want to group by a computed expression in an aggregation query. The trouble is, whenever you group by a computed expression, SQL Server considers the ordering of the data to be lost, and this will turn your buttery-smooth Stream Aggregate operation into a Hash Match (aggregate) or create a corrective Sort operation, both of which are blocking.
Is there anything we can do about this? Yes, sometimes, like when those computed expressions are YEAR() and MONTH(), there is. But you should probably get your nerd on for this one.
Consider the following table with accounting transactions, with a few million rows:
CREATE TABLE Finance.Transactions (
AccountID smallint NOT NULL,
AccountingDate date NOT NULL,
-- ... and a few other columns of lesser importance
Amount numeric(12, 2) NOT NULL,
-- This index actually shows as non-clustered in the
-- query plan images, but you get the picture. :)
CONSTRAINT IX_Finance_Transactions
PRIMARY KEY CLUSTERED
(AccountID, AccountingDate)
);
Say we want balances per account, per calendar month. That’s a simple enough query to write:
SELECT AccountID,
DATEFROMPARTS(
YEAR(AccountingDate),
MONTH(AccountingDate),
1) AS AccountingPeriod,
SUM(Amount) AS MonthlyChange
FROM Finance.Transactions
GROUP BY AccountID,
YEAR(AccountingDate),
MONTH(AccountingDate);
And here’s the query plan:

The problem here is with the Hash Match (aggregate) operator. Now, by “problem”, I mean that if the table is fairly large and your server instance is weak cheap, there will be potentially much memory grant and terrible spillage of disks.
I’ll admit, the memory grant was just a few MBs, and there was no spill to disk at all, but I’ll persist in my epic (and at first glance quite pointless) quest to eliminate blocking operators from this plan.
Just for the hell of it. Stay with me here, I’ll make it worth your while.
Right, where was I. I figure we’ll build this monster in layers. Our first task is to aggregate the data the best we can with the limitations at hand – i.e. not by year and month, but by accounting date. We’ll figure out the rest as we go along.
SELECT AccountID,
AccountingDate,
SUM(Amount) AS DailyTotal
FROM Finance.Transactions
GROUP BY AccountID, AccountingDate;
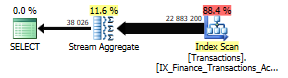
This is the simplest plan ever.
And let’s add a window aggregate to turn the DailyTotal column into running total over dates:
SELECT AccountID,
AccountingDate,
-- Running total by account over AccountingDate:
SUM(SUM(Amount)) OVER (
PARTITION BY AccountID
ORDER BY AccountingDate
) AS RunningTotal
FROM Finance.Transactions
GROUP BY AccountID, AccountingDate;
It’s more complex, but really not something we haven’t seen before. Because we’ve added a window function, we now have the usual collection of window operators, plus one more Stream Aggregate.

But now that we have running totals by AccountingDate, how can we turn them into monthly aggregates? By using the last running total of each month, and subtracting the running total of last month’s last date.
Let’s go ahead and create our own Segment operator of sorts. Using a window function (LEAD), we can peek ahead one row to see if this is the last TransactionDate of the month. If it is, we’ll keep it, otherwise, we’ll filter it out.
SELECT AccountID,
AccountingDate,
SUM(SUM(Amount)) OVER (
PARTITION BY AccountID
ORDER BY AccountingDate) AS RunningTotal,
-- Is this the same month as that of the next row?
(CASE WHEN DATEDIFF(month,
AccountingDate,
LEAD(AccountingDate, 1) OVER (
PARTITION BY AccountID
ORDER BY AccountingDate))=0
THEN 0 ELSE 1
END) AS IsLastDayOfMonth
FROM Finance.Transactions
GROUP BY AccountID, AccountingDate;
Things are starting to get messy in the query plan.

If it’s any consolation, there are still no blocking operators. Now, let’s filter out just the rows we want (the last row for each month), so there’s just a single row for each month, and subtract the previous month’s last running total.
We’ll just put our work so far in a common table expression and take it from there:
-- Common table expression (CTE) to package things up: WITH runningTotals AS ( SELECT AccountID, AccountingDate, SUM(SUM(Amount)) OVER ( PARTITION BY AccountID ORDER BY AccountingDate) AS RunningTotal, (CASE WHEN DATEDIFF(month, AccountingDate, LEAD(AccountingDate, 1) OVER ( PARTITION BY AccountID ORDER BY AccountingDate))=0 THEN 0 ELSE 1 END) AS IsLastDayOfMonth FROM Finance.Transactions GROUP BY AccountID, AccountingDate) SELECT AccountID, -- Pretty month format: DATEFROMPARTS( YEAR(AccountingDate), MONTH(AccountingDate), 1) AS AccountingMonth, -- This month's running total, minus -- that of last month is this month's -- change (i.e. the sum of Amount): RunningTotal-LAG(RunningTotal, 1, 0.0) OVER ( PARTITION BY AccountID ORDER BY AccountingDate) AS MonthlyTotal FROM runningTotals WHERE IsLastDayOfMonth=1;
And there it is. The plan looks like the endless tapeworm from a horror movie, but there’s no blocking operator. For one, that means it starts returning rows the second you click “Execute”. And it will scale linearly no matter how many rows you can throw at it.


Our refined (and slightly excentric) monster clocks in at 198 seconds on my dead-tired and very cheap Azure SQL Database instance. By comparison, that’s actually twice as fast as the original query. I get similar proportions on my 8-core VM, where the query goes parallel.
Performance tuning: 1. Windmills: 0
UPDATED:
Thank you all for the Twitter love and the comments. Here are a few things that surfaced:
Hugo’s partial aggregate
Hugo Kornelis suggested a partial aggregate, which technically isn’t non-blocking, but brings performance to about a similar level as my Don Quixote query. My interpretation of it:
WITH partialAgg AS (
SELECT AccountingDate, AccountID, SUM(Amount) AS Amount
FROM Finance.Transactions
GROUP BY AccountingDate, AccountID)
SELECT AccountID,
DATEFROMPARTS(
YEAR(AccountingDate),
MONTH(AccountingDate),
1) AS AccountingPeriod,
SUM(Amount) AS MonthlyChange
FROM partialAgg
GROUP BY AccountID,
YEAR(AccountingDate),
MONTH(AccountingDate);
This creates a two-step aggregation, where the first step creates a streaming (non-blocking) aggregate on (AccountingDate, AccountID), after which the relatively small output is hash aggregated to (year, month, AccountID).
Query statistics
Alex Friedman asked for the stats for the two queries.
On a DS4 v2 virtual machine (8 cores and not-sure-how-much-but-plenty of RAM) with SQL Server 2017 (build 14.0.3025.34), original query:
- Table ‘Transactions’. Scan count 9, logical reads 91185
- CPU time = 24032 ms, elapsed time = 3167 ms.
- Memory grant: 18 184 kB granted, 17 608 kB required
… and non-blocking query:
- Table ‘Transactions’. Scan count 9, logical reads 91701
- Table ‘Worktable’. Scan count 38080, logical reads 229006
- CPU time = 12796 ms, elapsed time = 1743 ms.
- Memory grant: 43 912 kB granted, 26 888 kB required
… and Hugo’s partial aggregate:
- Table ‘Transactions’. Scan count 9, logical reads 91711
- CPU time = 12343 ms, elapsed time = 1668 ms.
- Memory grant: 18 568 kB granted & required
To be honest, I was surprised to see such a memory grant (actually, any memory grant at all) on my non-blocking query, but as Hugo says in his comment, that’s probably the Spool.
On an Azure SQL Database, S0 tier, original query:
- Table ‘Transactions’. Scan count 1, logical reads 107675, physical reads 1, read-ahead reads 107673
- CPU time = 1657 ms, elapsed time = 219909 ms.
… and non-blocking:
- Table ‘Worktable’. Scan count 38080, logical reads 228999
- Table ‘Transactions’. Scan count 1, logical reads 107675, physical reads 0, read-ahead reads 107433
- CPU time = 1047 ms, elapsed time = 104359 ms.
… and Hugo’s partial aggregate:
- Table ‘Transactions’. Scan count 1, logical reads 107675, physical reads 0, read-ahead reads 105033
- CPU time = 1094 ms, elapsed time = 105316 ms.
Columnstore index
Finally, Uri asked what it would look like if we went full columnstore on the original query. I only ran this on the VM, as columnstore indexes are only supported on Premium Azure SQL Database instances:
- Table ‘Transactions_CCIX’. Scan count 8, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 10715
- Table ‘Transactions_CCIX’. Segment reads 22, segment skipped 0.
- CPU time = 7126 ms, elapsed time = 1005 ms.
- Memory grant: 25544 kB granted, 24712 kB required.
It’s about twice as fast as the non-blocking rowstore query.